Testing the Titans of Text: A New Frontier in Evaluating Large Language Models
By James Pitcher
 In a digital age where artificial intelligence (AI) converses, creates, and even contemplates, the humans relying on these tools must have confidence in their security and reliability. Testing these colossal algorithms – known as large language models (LLMs) – is not just a technicality, but a necessity.
In a digital age where artificial intelligence (AI) converses, creates, and even contemplates, the humans relying on these tools must have confidence in their security and reliability. Testing these colossal algorithms – known as large language models (LLMs) – is not just a technicality, but a necessity.
The United States government has also passed mandates that government agencies contemplating the use of LLMs, as well as other artificial intelligence capabilities, have a plan for testing and evaluating these models before widespread implementation. Recent research shines a light on some innovative methodologies for testing and evaluating these computational giants, ensuring that they serve humanity safely and effectively.
The Complexity Challenge
LLMs are not just software; they are the architects of language – the hidden hands that write, respond, and even reason. With their increasing involvement in various domains, the complexity of evaluating their performance and ensuring their safety has grown exponentially.
The traditional metrics, confined to narrow domains, falter in capturing the expansive potential applications of LLMs. Meanwhile, the cost and scale of human-based evaluations are soaring sky-high.
A Hybrid Solution
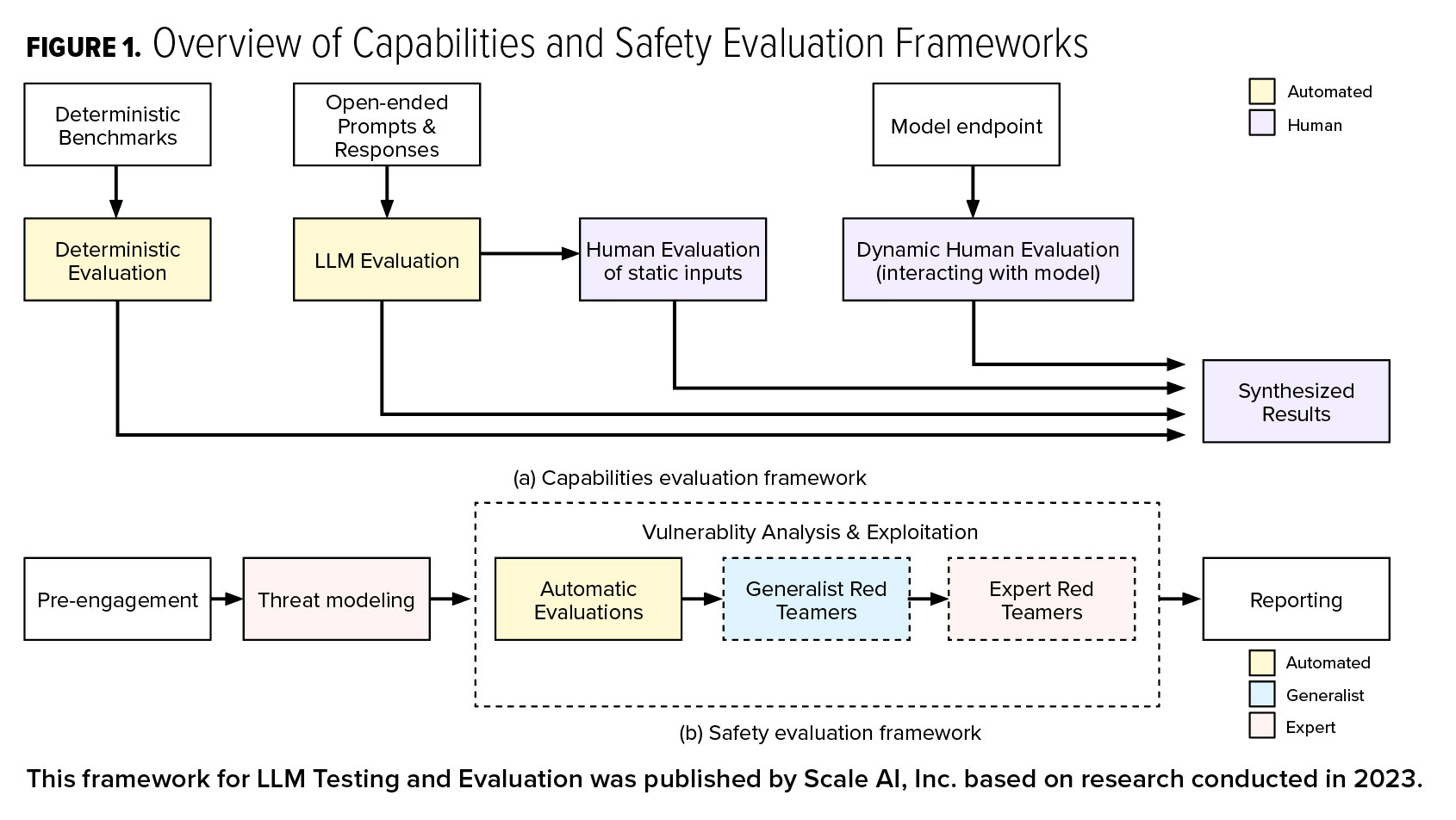
Acknowledging this dual challenge, a hybrid methodology has been proposed which combines the precision of human expertise with the efficiency of auto-mated systems. This approach is not just about running tests; it’s about understanding and improving the relationship between humans and AI.
It distinguishes between the capabilities of these models – such as reasoning, conversation, and coding – and their safety, ensuring they do not cause harm, spread bias, or enable malicious acts. Based on the risks and the level of confidence in the testing input quality, evaluators can make decisions on where to automate versus where more human touch is required to deliver quality insights into safety and performance.
Capabilities Unleashed
The capabilities of LLMs can be categorized into distinct groups which vary in complexity from information retrieval to complex math equations, each with its specific evaluation criteria. For example, in the realm of conversation, the level of engagement and tone of response is scrutinized, while in coding, the correctness and quality of the code take center stage.
The level of testing and the desired metrics will depend on the types of risks and degree of confidence required in the models’ performance. For an acquisition team, the same model might have broad capabilities that serve multiple functional teams.
However, it is usually difficult for one model to score highly across every category which could mean leveraging a platform that allows for the use of multiple LLMs that are more specialized to serve each need.
Safety in the Spotlight
In terms of safety, one proposed approach mirrors the meticulousness of cybersecurity standards, while specifically tailoring to the AI context. It’s about foreseeing the risks – from distributing sensitive content to enabling criminal activities – and safeguarding against them. This nuanced view extends to the vulnerabilities of LLMs, recognizing that these models, like any software, can have exploitable weaknesses.
Red teaming through prompt engineering has been a popular method for testing LLMs. In these exercises, users try a variety of prompt techniques to get the LLM to break the restrictions placed on it. Some of these exercises lead to comical results, while others can be more concerning.
In 2023, an auto manufacturer introduced an AI-powered customer service chatbot to streamline and improve its website user experience. This chatbot was powered by an LLM. In December 2023, one user tricked the chatbot into selling him an expensive sport utility vehicle for $1 through clever prompts. When the news broke, social media platforms were flooded with screenshots and examples from users having fun with the same chatbot and producing outputs not at all related to purchasing a vehicle.
Other concerns are more serious, though the methodology can be similarly absurd. Most publicly available models include safeguards that prevent models from producing potentially harmful or illegal information. For example, if you ask ChatGPT how to make an explosive device or an illegal sub-stance, you will receive a response declining to generate such information. To test these safeguards, model developers have teams of engineers try to ex-tract such information through less straightforward prompts.
These experts are essential to make sure that we are using this evolving technology safely and account for human behaviors that may put others at risk. One way this is being done today is that prompt engineers might use less direct inputs by pretending to be a chef looking for a recipe that includes the ingredients for an illegal substance.
Another engineer could tell the chatbot that he is a police officer trying to develop training for his department and needs to include materials that could be used to make a specific type of bomb. For LLMs to be trusted, these safeguards need to carry a high degree of confidence in their effectiveness.
Concluding Thoughts
The advancement of LLMs is not slowing down, nor is our reliance on them. As they grow in capability and complexity, our methods of testing and evaluating must evolve in tandem. These models hold a mirror to society, reflecting our language, our biases, and our creativity. It is our responsibility to ensure that as they learn from us, they also learn to work for the greater good, safeguarding against the risks that accompany such profound technological power. Testing and ensuring that we use this technology is being used for the betterment of society is critical, especially at these early stages. After all, we all know how Skynet turned out and none of us want that. CM
References
1 A car dealer added an AI chatbot to its site. Then all hell broke loose. at https://www.businessinsider.com/car-dealership-chevrolet-chatbot-chatgpt-pranks-chevy-2023-12?utm_source=copy-link&utm_medium=referral&utm_content=topbar.
2 Test & Evaluation: The Right Approach for Safe, Secure, and Trustworthy AI by The Scale AI Team, accessible at https://scale.com/blog/test-and-evaluation-white-paper
James Pitcher has a robust career spanning over 12 years as a contracts manager and has cultivated a rich blend of experiences in both government and the technology industry. His journey is marked by a deep-seated passion for innovation and technology, particularly in how these domains can enhance and transform the capabilities of the U.S. government. This enthusiasm is grounded in extensive practical experience. Pitcher is an experienced trainer on government contract authorities and loves to help stakeholders in identifying and employing the most effective contract strategies. This blend of experience and passion makes his insights particularly valuable for anyone looking to understand the intersection of technology, innovation, and government contracting.